最新读了一下 vue cli的源码,发现vue ui的实现很有意思,其中前后端通信用的是GraphQL,本着研究的态度,本人花了几天时间学习了GraphQL和集成框架Apollo Server。
本文用于总结学习过程。
什么是GraphQL
GraphQL是一种区别于JSON-RPC和REST的,针对 Graph(图状数据)进行查询比较有优势查询语言( Query Language )。
基本概念
schema
schema给我的感觉就是对整个GraphQL的定义。包括数据类型,数据存储格式,数据操作方式等。
举例说明:
我们想要查询一个班的男女生人数。那该怎么定义数据呢?
1 | type Class{ |
这里使用 type定义了一个对象类型,名字叫Class,其中包括 id,boy,girl三个字段。每个字段后面的ID和Number则表示该字段的类型,这里使用的是GraphQL给我们提供的基础标量类型。后面的!则表示该字段不能为空。
基础标量类型有这么几种:
Int:有符号 32 位整数。Float:有符号双精度浮点值。String:UTF‐8 字符序列。Boolean:true或者false。ID:ID 标量类型表示一个唯一标识符,通常用以重新获取对象或者作为缓存中的键。ID 类型使用和 String 一样的方式序列化;然而将其定义为 ID 意味着并不需要人类可读型。
除了这些类型,GraphQL还提供了查询类型(query),变更类型(mutation),自定义标量类型(scalar),枚举类型(enum),接口类型(interface),联合类型(union),输入类型(input)等,这里我们用到了再来介绍。
数据定义好了,那怎么查询呢?
这就需要用到查询类型(Query)了:
1 | type Query{ |
名称为class,返回类型为Class,即我们之前定义的对象类型。如果给类型加一个中括号,则代表返回一个该类型的数组。
那我们查询方法要怎么定义呢?这里引入另一个概念:resolver
resolver
resolver就是对schema中Query查询的操作函数。每个类型的每个字段都由一个 resolver 函数支持,当一个字段被执行时,相应的 resolver就会被调用。
如果字段产生标量值,如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。GraphQL 查询始终以标量值结束。
这个例子中我们的resolver如下,db是写死的对象数组,模拟本地数据库:
1 | class: () => { |
测试服务器搭建
准备完毕,我们在本地搭建一个服务器来测试GraphQL,这里使用koa做服务端。
完整代码如下:
1 | const Koa = require('koa'); |
之后我们进入本地服务器 localhost:5000/graphql,打开GraphQL提供的可视化查询界面。使用查询语句,就可以直接看到查询结果:
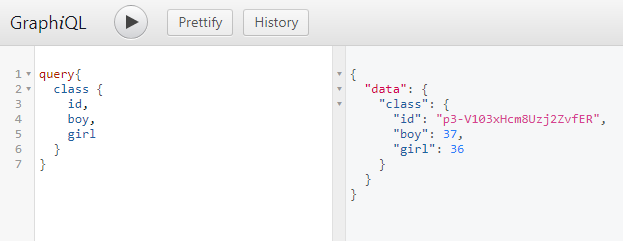
koaGraphql构方法中的rootValue其实就是resolver,它可以是一个函数
查询参数
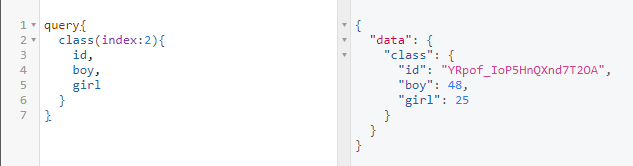
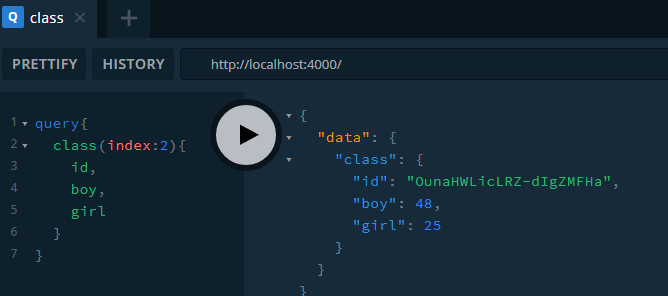
我们实现了一个简单的查询。那如果想根据索引来查询班级怎么办呢?这里需要给Query传参。
我们把query和resolvers进行一些改动:
1 | type Query { |
1 | class: (args,context,info) => { |
我们只需要在Query后的括号内指定参数的名称和类型即可,在后面可以给参数赋默认值。
而对于resolver,则会接受三个参数:
- args: 提供在 GraphQL 查询中传入的参数
- context:上下文信息,比如数据库访问对象等
- info:一个保存与当前查询相关的字段特定信息以及 schema 详细信息的值
这里我们使用args.index获取传过来的参数。
变更操作
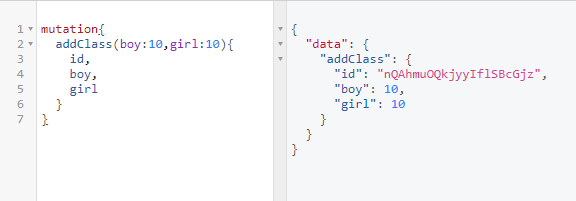
如果我们想添加一个班级呢?这就涉及到对数据的操作。GraphQL提供了Mutation这个类型来完成。同样是在schema中定义并在resolver中编写同名操作函数
1 | type Mutation{ |
1 | addClass:(args,context,info) => { |
mutation也可以有返回值,这里通常返回添加或操作之后的数据。我们这里就返回添加的班级。在可视化界面中可以看到插入数据成功。
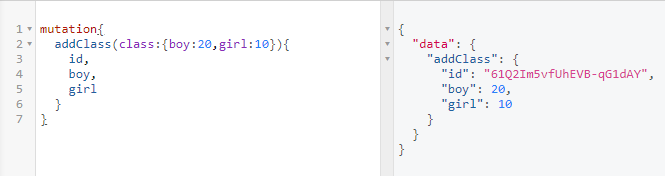
input 类型
input类型主要针对传入的参数,其实就是把参数封装成了一个对象便于使用。
这里我们把mutation的参数封装成input。
1 | input InputClass{ |
在args的对象里获取参数
1 | addClass:(args,context,info) => { |
这样就实现了参数的封装
其他类型
interface
interface接口,这个应该不陌生了。通过implements继承一个接口,可以添加新的数据,同时要实现接口中定义的所有数据。当要返回一个对象或者一组对象,特别是一组不同的类型时,就可以使用接口。union
联合类型和接口相似,但是它并不指定类型之间的任何共同字段,而是允许得到联合类型中的任意一个类型。我们这么定义它:
1
union Data = Class | Grade | School
在查询的时候,我们通过…on的方式针对不同类型返回不同的数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17search {
__typename
... on Class {
id
boy
girl
}
... on Grade {
id
level
classes
}
... on School {
id
grades
}
}
3. **enum**
枚举类型,返回可选集合中的某一个数据值
1
2
3
4
enum Identity {
STUDENT
TEACHER
}
Apollo Server
Apollo Server是一个开源的,符合规格的
GraphQL服务器,与任何GraphQL客户端兼容,包括Apollo Client。是用来构建可使用来自任何来源的数据的生产就绪、自记录GraphQL API的最佳方式。
它可以作为一个独立的GraphQL服务器,也可以当做服务器的中间件来使用。
安装
如果我们用Apollo Server做服务器,那么只需要安装apollo-server和graphql就可以了,如果当做中间件来使用,则需要根据服务器类型对应的中间件。常用的有:apollo-server-express,apollo-server-koa和apollo-server-hapi
更多类型可以在官方文档里找到
使用
在Apollo Server中,我们使用typeDefs定义数据格式,使用resolvers声明数据操作的方式。在resolvers中,需要把每一种操作方式单独放在指定的对象中,比如
1 | const resolvers = { |
这样对于编写代码而言也就更加清晰了。
resolvers接收四个参数 :parent, args, context, info,其他三个跟之前一样,第一个parent会返回当前查询字段所在类型的父对象,如果是Query或Mutation这种根节点类型,则会返回传递给构造函数的rootValue的值。
之后后我们把resolvers和typeDefs传给Apollo Server的构造函数拿到服务器实例对象,之后就可以监听端口了。
我们把之前的demo改造成Apllo Server的,完整代码如下:
1 | const {ApolloServer, gql} = require('apollo-server'); |
运行起来后我们在可视化界面中进行查询,成功获取结果。
其他
阅读源码时发现构造函数里还传递了其他几个参数(尤大使用的是apollo-server-express):
- schemaDirectives:自定义的指令
- dataSources:用于封装从特定源的获取数据的类,例如数据库或REST API。 这些类有助于解决操作时处理缓存,重复数据删除和错误。同时支持使用多个数据源
- tracing:node的配置,会产生日志文件
- cacheControl:express
- engine:对服务器的配置,已经被移除
- context:对象(或创建对象的函数)传递给执行特定操作的每个解析器。这使解析器能够共享有用的上下文,例如数据库连接。
- subscriptions:订阅。每当发生特定服务器端事件时,可以更新其结果。也就是说如果我们想在更新完数据后实时把更新后的全部数据展示在页面上,就可以使用订阅机制,不用手动再执行一遍查询。